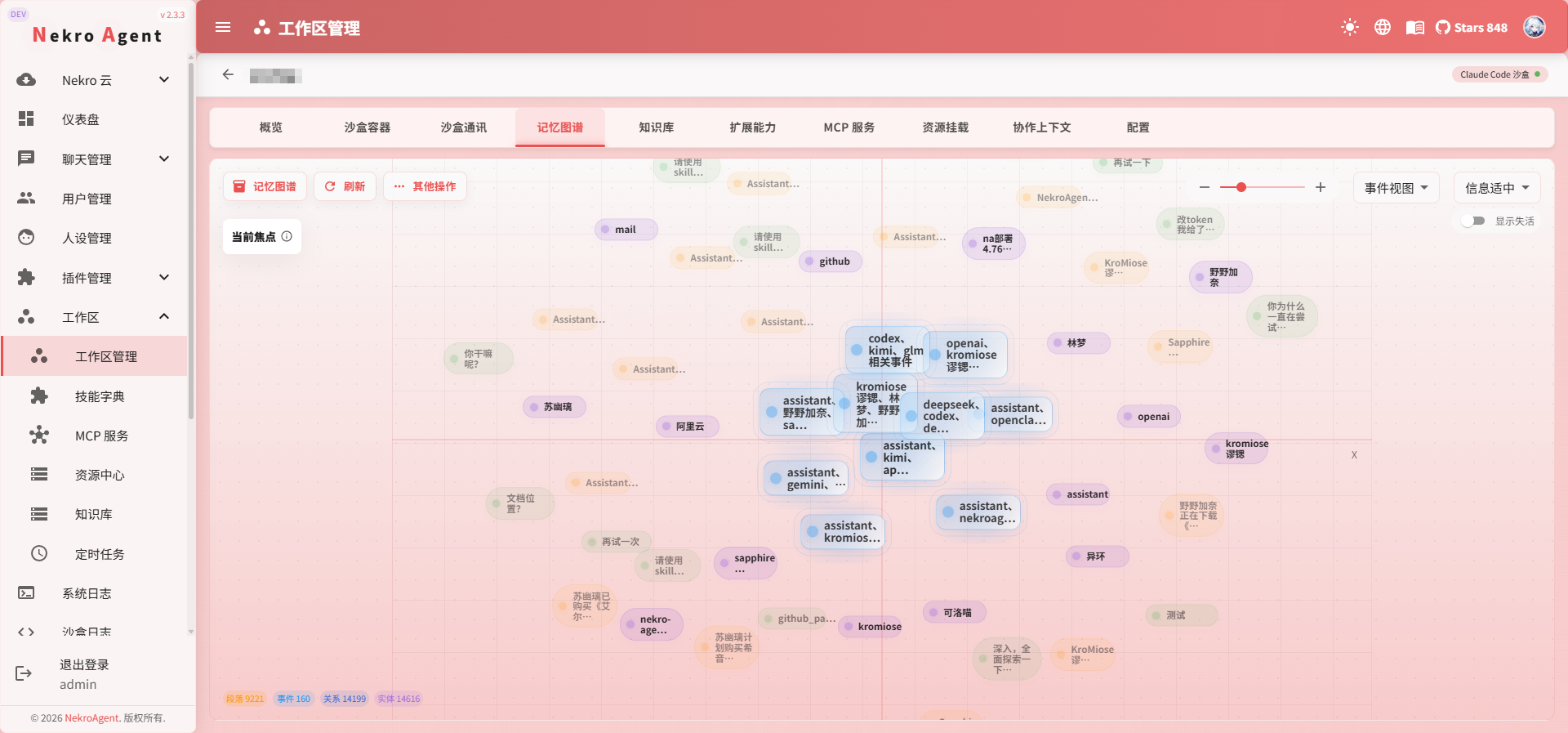
メモリシステム
CC サンドボックスへの依存:なし
ワークスペースへのバインド:必須
メモリシステムは AI に 長期記憶 を持たせます。
通常の対話が終了すると、AI は以前の会話内容を記憶していません。メモリシステムを有効にすると、ワークスペース内のすべての会話とタスクが自動的にメモリとして蓄積されます。次回のやり取りで、AI は以前の議論、好み、プロジェクトの背景を思い出すことができます。毎回説明し直す必要がなくなります。
これは、ワークスペースを長く使うほど、AI の理解が深まり、協働効率が向上することを意味します。
ハードルなしで使用可能
メモリシステムは Claude Code サンドボックスに依存しません。ワークスペースがありメモリスイッチがオンになっていれば、すぐにメモリの蓄積を開始できます。
メモリシステムがもたらすもの
背景説明の繰り返しが不要に
「うちのプロジェクトは FastAPI + PostgreSQL を使っている」「前回議論した案は A」——これらは一度だけ言えば済みます。メモリシステムが自動的にこれらの重要な情報を抽出して保持します。
AI のプロジェクト理解が継続的に深化
会話のたびに AI の理解に深みが加わります。数週間使用したワークスペースでは、AI のプロジェクト構造、技術スタック、ビジネスロジックの理解は新規作成された対話をはるかに超えます。
CC サンドボックスの経験が自動的に蓄積
CC サンドボックスが複雑なタスクを完了すると、得られた結論と経験が自動的に 意味メモリ として蓄積され、長期的に再利用可能なナレッジとなります。例えば「プロジェクトの認証モジュールは /src/auth/ にあり、JWT + Redis 方式を使用」などです。
複数チャンネルでメモリを共有
同じワークスペースにバインドされた複数のチャンネルはメモリを共有します。チームメンバーが異なるチャンネルで質問しても、AI は同じメモリに基づいて一貫した回答を提供します。
AI が記憶する内容
メモリシステムはワークスペース内の長期コンテキストを自動的に整理します。一般的な内容は以下の通りです:
| タイプ | 例 |
|---|---|
| プロジェクト背景 | プロジェクトの用途、技術スタック、よく使うコマンド、デプロイ方法 |
| メンバーと好み | 担当分野、よく使う表現習慣、出力フォーマットの好み |
| 過去の決定 | 以前議論した案、除外した選択肢、最終結論 |
| タスク経験 | Claude Code サンドボックスがタスク完了後にまとめた安定した経験 |
| 重要な出来事 | 要件変更、問題調査プロセス、マイルストーン会議の結論 |
これらのメモリは以降の会話で自動的に参考にされます。「どのメモリを参照するか」を手動で指定する必要はなく、同じワークスペースで継続的に使用するだけです。
メモリの仕組み
自動蓄積
メモリの蓄積は完全に自動で、手動操作は不要です。システムはワークスペース内の会話とタスク結果を定期的に整理し、長期的に保持すべき情報をメモリに変換します。
デフォルトでは、以下の場合に整理がトリガーされます:
- 新しいメッセージがある数に達した場合
- 前回の整理から一定時間が経過した場合
- Claude Code サンドボックスが蓄積可能なタスク結論を完了した場合
自動想起
AI が新しいメッセージやタスクを処理する際、現在の問題に基づいて関連メモリを自動的に検索し、有用な情報を回答に取り込みます。
AI が特定の内容を思い出していない場合は、以下を試してください:
- 同じワークスペースで追加質問し、キーワードを補足する
- メモリシステムが有効になっていることを確認する
- embedding モデルグループが利用可能か確認する
- 必要に応じてメモリ再構築を実行する
自動クリーンアップ
メモリは多ければ多いほど良いというものではありません。長期間関連性が低く、ほとんど言及されない情報は優先度が徐々に下がり、繰り返し使用される重要な情報はより呼び出しやすくなります。
前提条件
メモリシステムの有効化には以下が必要です:
MEMORY_ENABLE_SYSTEMをtrueに設定(システム設定 → 基本設定)- 利用可能な embedding モデルグループの設定(
MEMORY_EMBEDDING_MODEL_GROUP) - embedding 次元がモデルと一致することを確認(
MEMORY_EMBEDDING_DIMENSION、デフォルト 1024) - メモリ整理用モデルグループの設定(
MEMORY_CONSOLIDATION_MODEL_GROUP) - デプロイ環境のベクトルデータベースサービスが正常に動作していることを確認
メモリ再構築
メモリデータに異常が発生した場合、または履歴メッセージからメモリを再抽出したい場合は、メモリ再構築を使用できます。
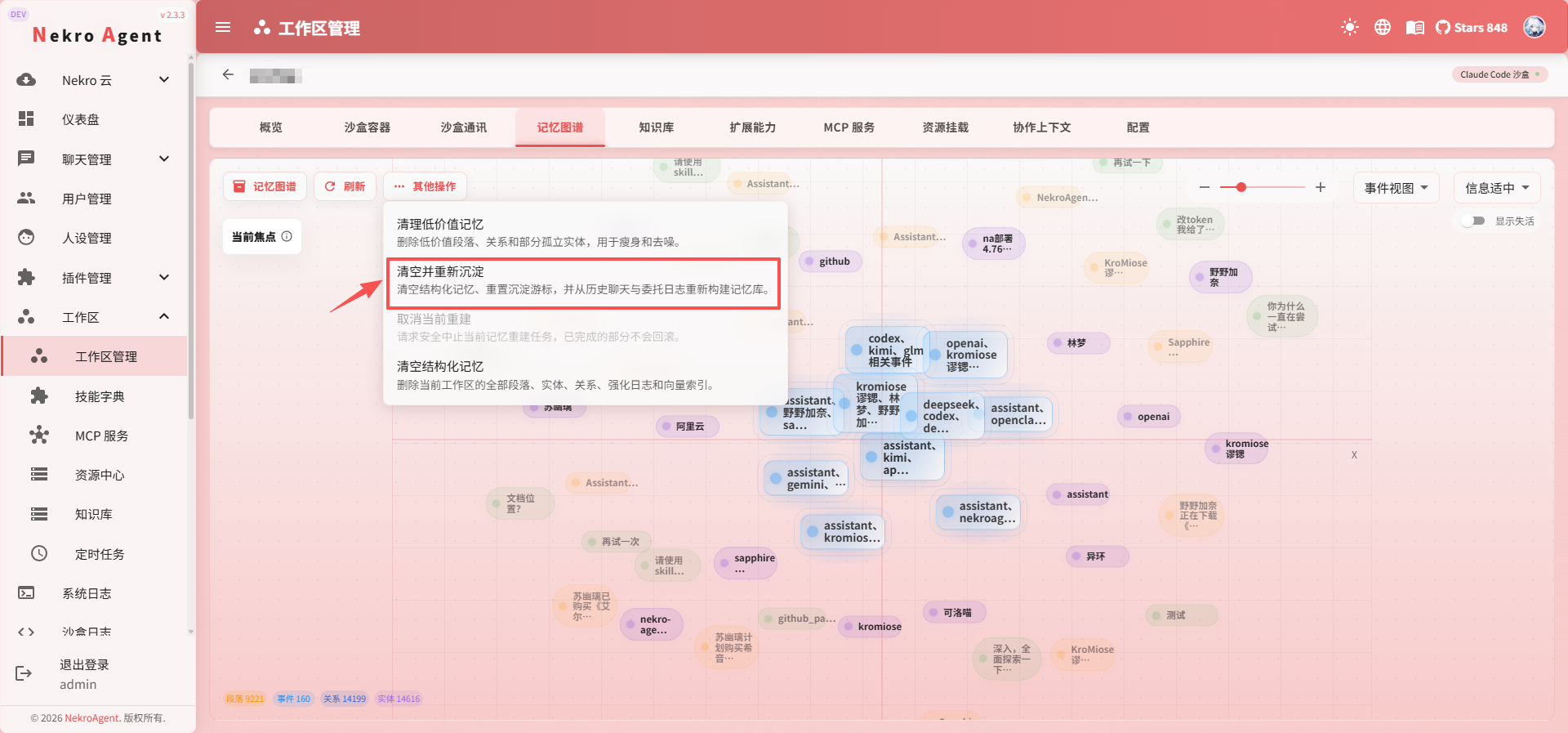
再構築では現在のワークスペースのメモリがクリアされ、履歴メッセージから再蓄積されます。デフォルトでは30日間遡及します(MEMORY_REBUILD_LOOKBACK_DAYS で設定可能)。
再構築コスト
メモリ再構築は多くの LLM コールと時間を消費します。ピーク時間を避け、本当に必要な場合にのみ使用することをお勧めします。
主要設定項目
| 設定項目 | デフォルト値 | 説明 |
|---|---|---|
MEMORY_ENABLE_SYSTEM | false | メモリシステムのマスタースイッチ |
MEMORY_CONTEXT_MAX_LENGTH | 1200 | 1回の回答で参照する最大メモリコンテンツ長 |
MEMORY_CONSOLIDATION_MSG_THRESHOLD | 50 | メッセージ何件蓄積後に自動整理するか |
MEMORY_CONSOLIDATION_TIME_THRESHOLD_HOURS | 2.0 | 前回の整理から何時間後に自動整理するか |
MEMORY_RETRIEVAL_DEFAULT_LIMIT | 10 | 1回に参照する最大候補メモリ数 |
MEMORY_RETRIEVAL_MIN_SIMILARITY | 0.5 | メモリマッチングの最低関連度 |
MEMORY_PRUNE_ENABLED | true | 長期的に不要なメモリを自動クリーンアップするか |
完全な設定項目の説明は システム設定 を参照してください。
使用のヒント
- 早めに有効化:ワークスペース作成後にメモリシステムを有効化することをお勧めします。早めに蓄積を開始するほど、AI の理解が深まります
- 安定性を保つ:長期ワークスペースのメモリは使うほど価値が高まります。頻繁な再構築は避けてください
- 具体的に記述:AI との会話ではコンテキストをできるだけ明確に記述してください。メモリシステムがより正確な情報を抽出するのに役立ちます
- ナレッジベースとの連携:ナレッジベースは静的資料を保存し、メモリシステムは動的コンテキストを蓄積します。二者は相互補完的です
- 効果に基づくチューニング:AI が関連コンテンツを思い出せない場合は、候補メモリ数を適度に増やすか、拡張検索(
MEMORY_ENABLE_ENHANCED_RETRIEVAL)を有効化してみてください
関連ドキュメント
- ワークスペース概要
- ナレッジベース — 静的ナレッジ。動的メモリと相互補完
- Claude Code サンドボックス — CC タスクの結論が自動的に意味メモリとして蓄積
- システム設定