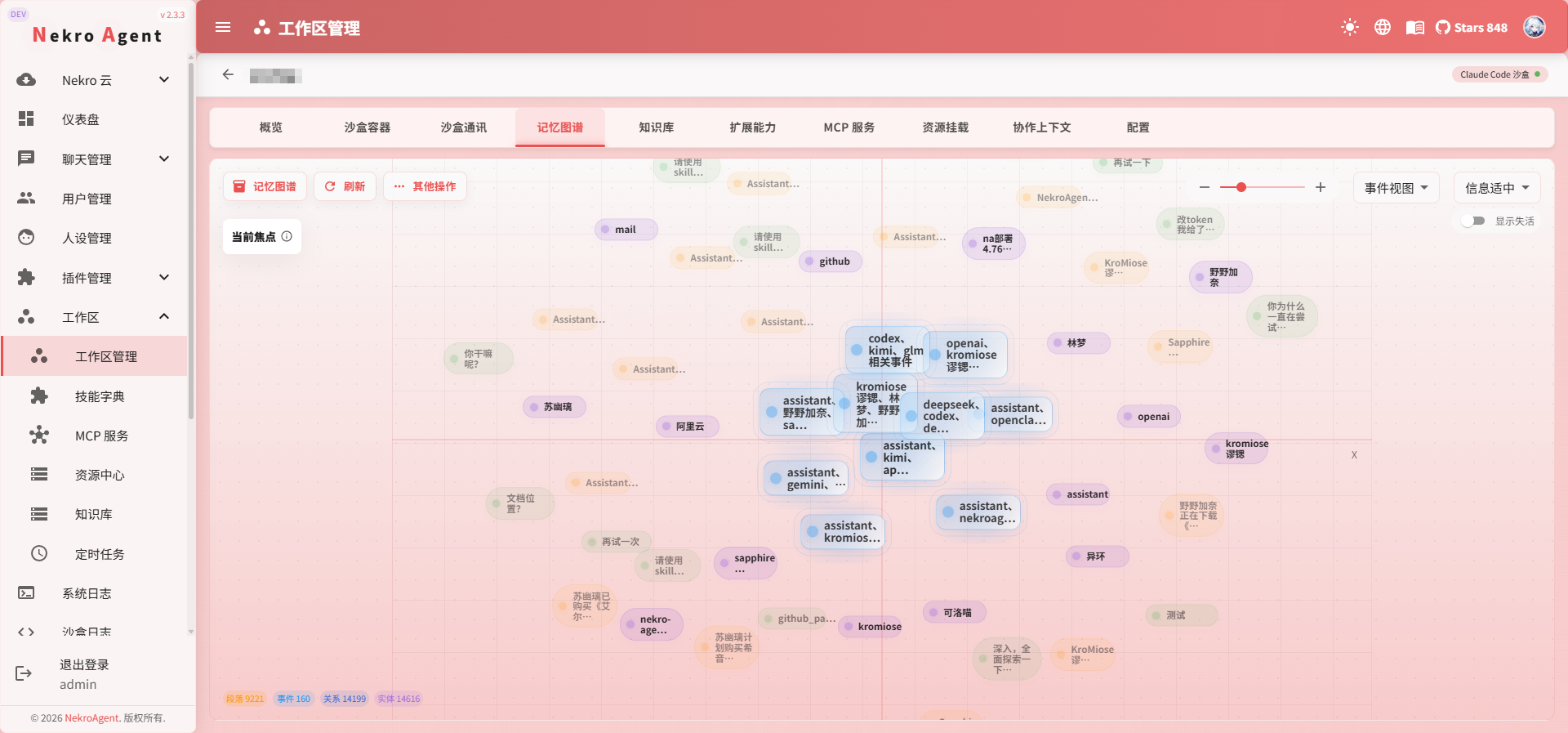
记忆系统
是否依赖 CC 沙盒:否
是否必须绑定工作区:是
记忆系统让 AI 拥有长期记忆。
普通对话结束后,AI 不会记住之前聊过什么。启用记忆系统后,工作区中的每次对话和任务都会自动沉淀为记忆。下次交流时,AI 能回忆起之前的讨论、您的偏好、项目的背景——不再需要每次都从头交代。
这意味着工作区用得越久,AI 对您的理解越深,协作效率越高。
零门槛使用
记忆系统不依赖 Claude Code 沙盒。只要有工作区并启用记忆开关,就可以立即开始积累记忆。
记忆系统能带来什么
不再反复交代背景
「我们项目用的是 FastAPI + PostgreSQL」「上次讨论的方案是 A」——这些您只需要说一次。记忆系统会自动提取并保留这些关键信息。
AI 对项目的理解持续加深
每次对话都在为 AI 的理解增加深度。一个使用了几周的工作区,AI 对项目结构、技术栈、业务逻辑的理解远超新建的对话。
CC 沙盒的经验自动沉淀
当 CC 沙盒完成一个复杂任务后,得出的结论和经验会自动沉淀为语义记忆,成为长期可复用的知识。例如「项目的认证模块在 /src/auth/,使用 JWT + Redis 方案」。
多频道共享记忆
绑定到同一个工作区的多个频道共享记忆。团队成员在不同频道提问,AI 都能基于同一套记忆给出一致的回答。
AI 会记住什么
记忆系统会自动整理工作区中的长期上下文,常见内容包括:
| 类型 | 示例 |
|---|---|
| 项目背景 | 项目用途、技术栈、常用命令、部署方式 |
| 成员与偏好 | 谁负责什么、常用表达习惯、输出格式偏好 |
| 历史决定 | 之前讨论过的方案、已经排除的选择、最终结论 |
| 任务经验 | Claude Code 沙盒完成任务后总结出的稳定经验 |
| 重要事件 | 需求变更、问题排查过程、阶段性会议结论 |
这些记忆会在后续对话中自动参与参考。您不需要手动指定“查哪条记忆”,只需要在同一个工作区里持续使用即可。
记忆如何生效
自动沉淀
记忆沉淀完全自动,无需手动操作。系统会定期整理工作区中的对话和任务结果,把适合长期保留的信息转成记忆。
默认情况下,以下情况会触发整理:
- 新消息积累到一定数量
- 距离上次整理已经过去一段时间
- Claude Code 沙盒完成了可沉淀的任务结论
自动回忆
AI 处理新消息或新任务时,会根据当前问题自动查找相关记忆,并把有用的信息带入回答中。
如果您发现 AI 没有想起某些内容,可以尝试:
- 在同一个工作区继续追问,并补充关键词
- 确认记忆系统已经启用
- 检查 embedding 模型组是否可用
- 必要时执行记忆重建
自动清理
记忆不是越多越好。长期不再相关、很少被提及的信息会逐渐降低优先级;反复被使用的重要信息会更容易被召回。
前置条件
启用记忆系统需要:
- 将
MEMORY_ENABLE_SYSTEM设为true(系统配置 → 基本配置) - 配置可用的 embedding 模型组(
MEMORY_EMBEDDING_MODEL_GROUP) - 确认 embedding 维度与模型匹配(
MEMORY_EMBEDDING_DIMENSION,默认 1024) - 配置用于记忆整理的模型组(
MEMORY_CONSOLIDATION_MODEL_GROUP) - 确认部署环境中的向量数据库服务正常运行
记忆重建
如果记忆数据出现异常,或希望从历史消息中重新提取记忆,可以使用记忆重建。
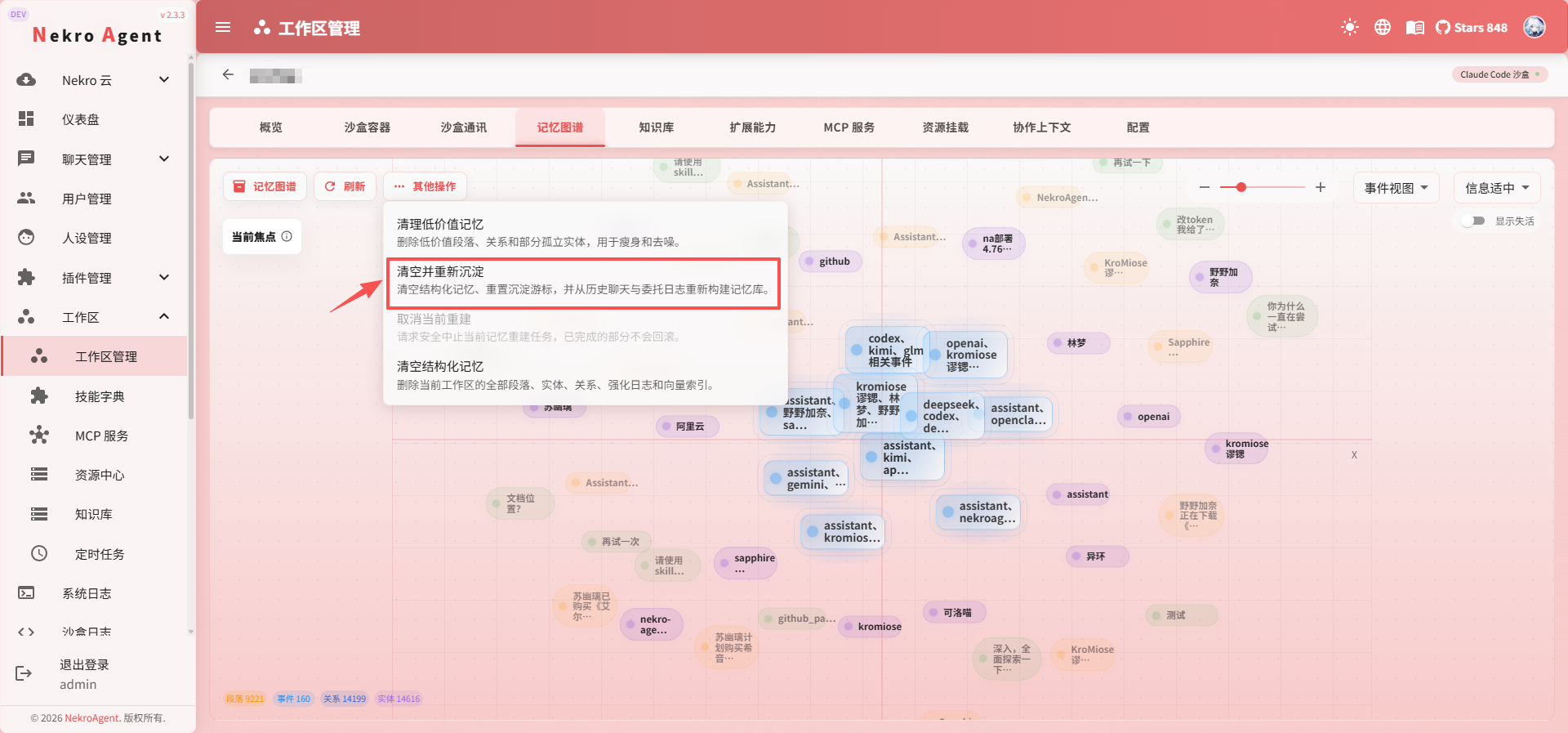
重建会清除当前工作区的记忆并从历史消息中重新沉淀。默认回溯 30 天(可通过 MEMORY_REBUILD_LOOKBACK_DAYS 配置)。
重建成本
记忆重建会消耗较多的 LLM 调用和时间。建议在非高峰期执行,且仅在确实需要时使用。
关键配置项
| 配置项 | 默认值 | 说明 |
|---|---|---|
MEMORY_ENABLE_SYSTEM | false | 记忆系统总开关 |
MEMORY_CONTEXT_MAX_LENGTH | 1200 | 单次回答最多参考的记忆内容长度 |
MEMORY_CONSOLIDATION_MSG_THRESHOLD | 50 | 积累多少条消息后自动整理记忆 |
MEMORY_CONSOLIDATION_TIME_THRESHOLD_HOURS | 2.0 | 距上次整理多久后自动整理记忆 |
MEMORY_RETRIEVAL_DEFAULT_LIMIT | 10 | 单次最多参考多少条候选记忆 |
MEMORY_RETRIEVAL_MIN_SIMILARITY | 0.5 | 记忆匹配的最低相关度 |
MEMORY_PRUNE_ENABLED | true | 是否自动清理长期无用的记忆 |
完整配置项说明参见 系统配置。
使用建议
- 尽早开启:工作区创建后就建议启用记忆系统,越早开始积累,AI 的理解越深
- 保持稳定:长期工作区的记忆越用越有价值,避免频繁重建
- 描述具体:与 AI 对话时尽量描述清楚上下文,有助于记忆系统提取更准确的信息
- 与知识库配合:知识库存放静态资料,记忆系统积累动态上下文,两者互补
- 按效果调优:如果 AI 经常想不起相关内容,可以适当提高候选记忆数量或开启增强检索(
MEMORY_ENABLE_ENHANCED_RETRIEVAL)
相关文档
- 工作区总览
- 知识库 — 静态知识,与动态记忆互补
- Claude Code 沙盒 — CC 任务结论自动沉淀为语义记忆
- 系统配置