ナレッジベース
CC サンドボックスへの依存:なし
ワークスペースへのバインド:必須
ナレッジベースは AI に 専門ドメイン知識 を持たせます。
ドキュメント、マニュアル、資料をワークスペースのナレッジベースにアップロードすると、AI はタスク処理時に自動的に関連コンテンツを検索して引用します。資料を毎回会話に貼り付ける必要はなく、ナレッジベースが AI に常に専門資料を提供します。
ハードルなしで使用可能
ナレッジベースは Claude Code サンドボックスに依存しません。ワークスペースがあれば、すぐにナレッジベースを使用できます。CC サンドボックスの実行機能がまだ不要な場合でも、資料をナレッジベースに整理するだけで AI の回答品質を大幅に向上できます。
ナレッジベースがもたらすもの
AI をドメインエキスパートに
プロジェクトドキュメントをアップロードすると、AI は質問回答時に自動的にナレッジベースを参照し、実際の資料に基づいた回答を提供します。一般的な回答ではなくなります。
繰り返しの説明コストを削減
毎回の会話で大量の背景資料を貼り付ける必要がなくなります。ナレッジベースはワークスペースに常駐し、AI は毎回検索できます。
ナレッジの多人数共有
複数のチャンネルが同じワークスペースにバインドされている場合、すべてのチャンネルの AI が同じナレッジベースにアクセスでき、情報の一貫性が保証されます。
ナレッジベースに適したコンテンツ
| タイプ | 例 |
|---|---|
| プロジェクトドキュメント | アーキテクチャ設計ドキュメント、API ドキュメント、技術仕様 |
| 操作マニュアル | デプロイガイド、運用マニュアル、使用チュートリアル |
| ナレッジベース資料 | 業界知識、製品説明、FAQ 集 |
| 参考資料 | 論文、リサーチレポート、規格標準 |
| 長期テキスト | 会議録、プロジェクト週報、要件ドキュメント |
前提条件
ナレッジベースの使用前に、以下の設定が完了していることを確認してください:
- Embedding モデルグループ:「システム設定」→「基本設定」で、
KB_EMBEDDING_MODEL_GROUPに利用可能な embedding モデルグループを設定 - Embedding 次元:
KB_EMBEDDING_DIMENSIONが選択したモデルの出力次元と一致することを確認(デフォルト 1024)
使用方法
ファイルのアップロード
ワークスペースのナレッジベースページに入り、アップロードエントリからファイルを追加します。ファイルのアップロード後、自動的にチャンク分割とベクトル化処理が行われます。
管理エントリ
ナレッジベースは2段階の管理ビューを提供します:
- グローバルナレッジベース:「ナレッジベース」ページで全ワークスペースのナレッジベースファイルを確認
- ワークスペースナレッジベース:ワークスペースに入り、現在のワークスペースのナレッジベースファイルを管理
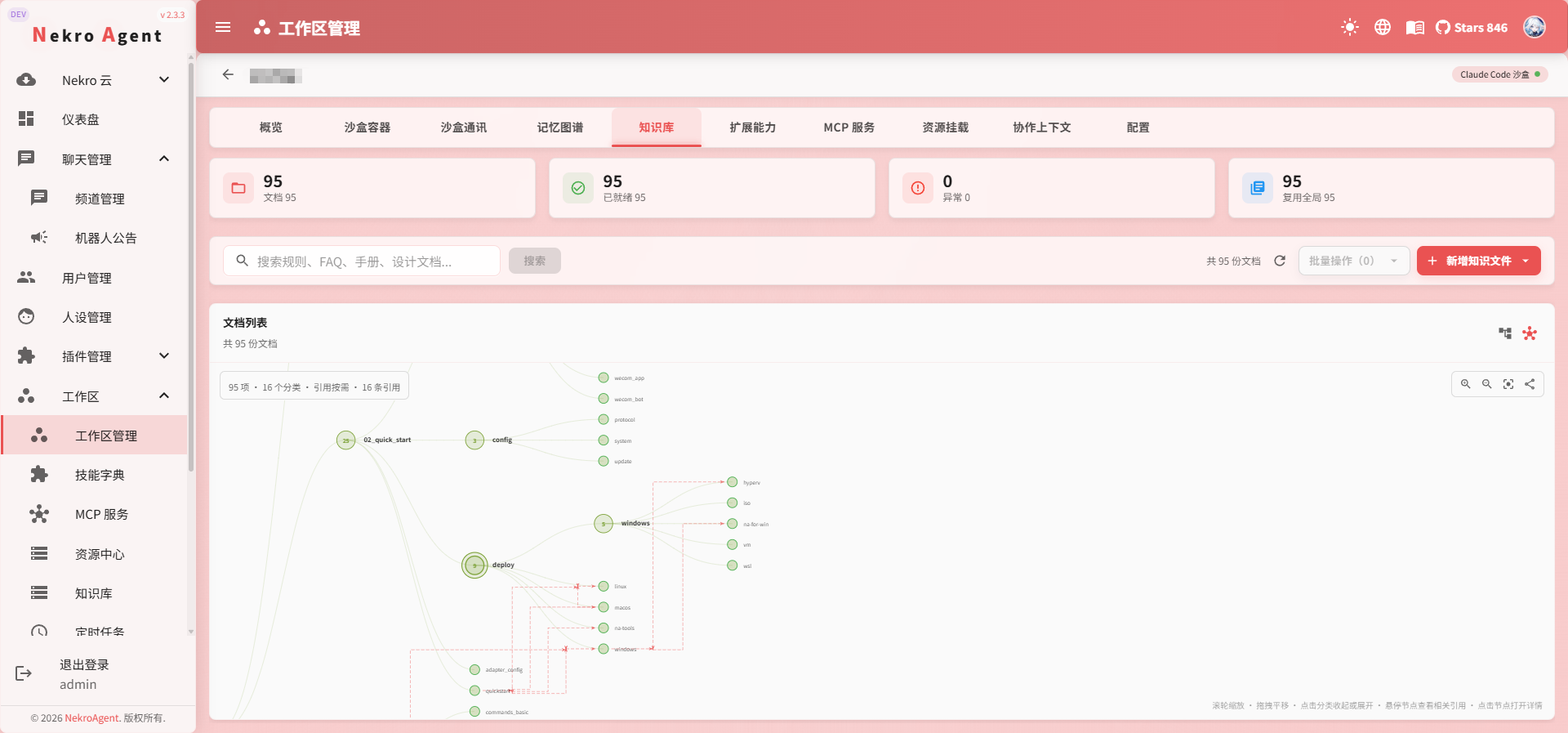
ファイルと引用の管理
ナレッジベースのファイルはアップロード後、解析、チャンク分割、ベクトル化のプロセスに入ります。処理完了後、AI が対応するコンテンツを安定して検索できるようになります。
一般的な操作:
| 操作 | 説明 |
|---|---|
| ワークスペースへのバインド | 指定ワークスペースがこの資料を検索できるようにする |
| ワークスペースのアンバインド | 資料はグローバルナレッジベースに残るが、現在のワークスペースでは使用されなくなる |
| 引用の確認 | 資料がどのワークスペースやコンテンツから引用されているかを確認 |
| インデックス再構築 | ファイル内容の更新や検索異常時に、ベクトルインデックスを再生成 |
| ファイルの削除 | 不要な資料を削除。削除前に他のワークスペースが依存していないことを確認 |
同じ資料を複数のプロジェクトで再利用する場合は、まずグローバルナレッジベースに入れてから、必要に応じて異なるワークスペースにバインドすることをお勧めします。
サポートされる資料タイプ
ナレッジベースは長期的に安定したテキスト資料の保存に適しています。一般的なフォーマットには Markdown、TXT、PDF、DOCX、XLSX などがあります。デプロイ環境によってドキュメント解析機能に若干の差異がある場合があります。ページのアップロード結果をご確認ください。
ファイルのアップロード後に解析に失敗した場合は、以下を試してください:
- ファイルを PDF または Markdown として保存し直す
- 過大なドキュメントを分割する
- 複雑なレイアウト、スキャン画像ページ、保護されたコンテンツを除去する
- ログセンターで解析エラーを確認する
自動検索
AI がタスクを処理する際、現在の質問に基づいてナレッジベースへのクエリが必要かどうかを自動的に判断し、関連資料を引用して回答します。
通常、ファイル名を手動で指定する必要はありません。資料がアップロードされ、処理が完了し、現在のワークスペースにバインドされていれば、AI は必要時に検索できます。
AI が1回の回答で参照できるナレッジベースのディレクトリ数を調整したい場合は、「プラグイン管理」→「ナレッジベースツール」→「設定」で関連オプションを変更できます。
使用のヒント
- 早めにアップロード:ワークスペース作成後すぐに資料のアップロードを開始できます。CC サンドボックスの設定を待つ必要はありません
- ワークスペース単位で整理:異なるプロジェクトの資料は異なるワークスペースに入れ、ナレッジの境界を明確に保つ
- 継続的に追加:ナレッジベースにはいつでもファイルを追加でき、新しくアップロードされたコンテンツは自動的にベクトル化される
- チャンク品質に注意:検索結果が期待に沿わない場合は、長文ドキュメントをテーマ別に分割してからアップロードしてみる
- embedding 設定の確認:アップロード後にコンテンツが検索できない場合は、まず embedding モデルグループと次元設定を確認
関連ドキュメント
- ワークスペース概要
- メモリシステム — 自動的に蓄積される動的メモリ。ナレッジベースの静的資料と相互補完
- Claude Code サンドボックス
- システム設定 — embedding 関連の設定説明